
The Standard+Case approach: applying Case Management to ITSM
 Here is an exciting new approach to categorising and resolving any sort of activity "tickets", such as requests (including incidents) on a service desk, problems, or changes. It is called Standard+Case until somebody comes up with a better name. I know there is so much to read these days, but if you have anything to do with service support or change management, read this. It'll change your year.
Here is an exciting new approach to categorising and resolving any sort of activity "tickets", such as requests (including incidents) on a service desk, problems, or changes. It is called Standard+Case until somebody comes up with a better name. I know there is so much to read these days, but if you have anything to do with service support or change management, read this. It'll change your year.
Standard+Case is a synthesis of our conventional "Standard" process-centric approach to responding, with Case management, a discipline well-known in some other industry sectors such as health, social work, law and policing.
S+C addresses criticisms of approaches like ITIL for being too process-centric and not allowing customers and knowledge workers to be empowered. S+C does not seek to replace or change ITIL or other theory: it expands and clarifies that theory to provide a more complete description of managing responses.
It provides a good skills path for service desk analysts that fits well with gamification. And Standard+Case is applicable to Problem Management and Change Management (and Event Management...) as well as Service Desk activities. S+C applies to anything that requires a human response: there's either a standard response or there isn't.
For more information about Standard + Case, see the Basic Service Management website.

 Made in New Zealand
Made in New Zealand 

Comments
Some thoughts from a non-purist
I have always wrestled with the degree of granularity used in defining ITIL processes. Increased granularity provides more detail and nuance, but it risks information overload and sometimes can result in a check list mentality where value gets lost in the details.
I am a firm advocate of the KISS principle, at least in defining local practices -- especially where resource, generally human, constraints exist. I want to be careful, yet efficient, in defining roles and responsibilities... and processes.
My thinking on this is that I have wanted effective tools for tracking workload to individuals. Since the technical specialists in my shop were not often dedicated to servicing requests, incidents, problems, changes, etc. I wanted a common tool for managing these disparate processes. We tried to develop our own, but at the time I left, the ticketing system remained a work in progress.
In my view, everything we worked on was an "event." We used different methods or processes for handling each type of event. Thus, our network monitoring system might fire off an "incident event" and the change management system might fire off a "change event." We would then worked with the technical analysts to determine the best approach to prioritizing all of the events to which he or she was assigned.
We did not have SOA and our ticketing system leaned toward a case management approach. But we were starting to collect data on events over time that would have permitted some more structured processing of selected types of events.
I guess in conclusion, I see the value in distinguishing between standard and case events.
splits neatly
"Event" of course means something more narrow to this audience.
But if you mash requests (including incidents), problems, RFCs, and operational events together as all "tickets" to be dealt with, then yes that whole mashup splits neatly into Standard+Case.
You remind me that Event is a ticket that can also be dealt with by Standard+Case.
Meta-Process
Just to add a few thoughts on this thread about S+C for ITSM.
First of all, I had an email conversation with Rob talking about the concept of "Standard Incident" and the need to push the concept of problem management. He convinced me that in the real world, there is plenty of standard incidents, managed by people at the service desk.
Yes, that is true. But as this blog post says, probably a "standard incident" is the same concept as a known error (it's a problem, it has a known workaround. No, I don't agree with ITIL on the point that a KE must have a known root cause).
The other thought I wanted to share here is the idea of Meta-Process. I don't know if we can freely use that word, but I will act as if we can. When I explain to students the need for process design and we are talking about incident management or problem management, it's quite easy if you have an experienced audience, that they end arguing that it is impossible to formalize how do they solve the incidents. My answer to this situation (before I learnt about ACM from Charlie Betz and from Rob) was to explain them that what we can do is to define a meta-process, something like an envelope.
Let me explain: independently of what kind of service request you receive, you will need to register, assess, prioritize and classify it. You can standardize the steps needed to do this, you can define a process as BPM says here.
Then you arrive to the phase where you must "attend the request"; if it is what ITIL calls a "service request" (a standard) then you must follow the predefined steps to process the request (for example, if you are asked to increase mail quota, you follow specific steps to approve and execute the quota increase).
On the other hand, if you receive a non-standard request (an incident in ITIL words, a Case here) then... almost 100% of IT shops have defined a box in their process diagram that says "investigate & diagnosis" or "incident resolution". THAT is ACM. We have this box because we can not describe predefined steps to investigate, diagnose and solve an incident.
Then, once we have found and may be applied a solution, we continue with a standard process, usuaally a 2 steps closing model (solve and close).
So we have standard process for almost all the incident management, except for the important thing that is ACM, and this is what I call Meta-Process... the envelope of a case is an incident management process. And it happens exactly the same for Problem Management, where we can prepare an standard envelope, but the letter is handwritten and different each time.
The really big value that this thread is creating is that we are opening the "investigate & diagnose" or the "resolve incident" box and trying to find methods, techniques, models to apply here. This is really important because from a Lean point of view the only activities that adds customer value to an incident management process are diagnosis and solution... all the rest is NVA or NNVA (non value added or needed non value added), waste (from the customer point of view).
Well.. I hope this can add more light to this fascinating and really game-changer thread. Thanks Rob!
Process orientation
Academics are likely the worst about splitting hairs and defining terms, however... I am not sure that the term meta-process is required. In the operations management literature, processes are recognized as being more structured versus less structured. Hence a less structured process is still a process. I do not think that we need to discard a process orientation (at least not completely) to process cases.
I wonder if our emphasize on BPM and SOA have distorted some of the long term thinking about and learning about process management.
we abandon process completely
I'm not sure exactly where your thinking is at John, and I know you think deeply about this, having read a draft of your new book :)
At a crude level (where I always operate) we abandon process completely for the resolution phase of a Case ticket - one where by definition there is no predefined model - because:
We may choose to dynamically assemble process fragments at runtime but that's not the same as having a process.
We use the same process for both Standard and Case responses for all steps except Resolution
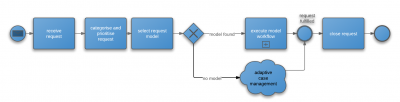
So i think it is fair to say Standard+Case is about having no process at all for the Resolve step in Case tickets (so I used a fuzzy cloud not a process box), and otherwise process is pretty much unchanged.
No process?
Hmm, again. I guess I still have a problem with "no process" although we might just be wrestling with an issue of granularity in our definitions. I have long been in the data networking business (ugh, even before internet). Working for the DoD, we were highly reliant on technical control facilities to troubleshoot transmission media failures. One of the worst things that can happen is when young technical controllers (on both ends of the circuit) would start throwing in loopbacks all over the place, sometimes introducing more errors, sometimes restoring service before they knew what was wrong, i.e., we dreaded the number of "cleared while testing" reports we received.
In many case-based activities, there are still steps. Almost certainly, you want to diagnose problems before you start throwing fixes into the system. Depending on the type of incident that you are addressing, the diagnosis process may be more or less structured. Under change management, or certain SLAs, the service provider may need to include steps that ensure impacted parties are notified of outages or changes.
I have neither been a lawyer or medical Dr. But my experience is that even doctors and lawyers will have some degree of standardized routine so they can efficiently get down to the actual management of the case. Granted, the actual diagnostic and resolution processes may be more or less, perhaps even completely unstructured. But that is not my personal experience. All a process is is some type of input, transformation and output. I certainly will not argue the fact that the transformation may be more or less structure (cloudlike) and that we err when we try to over-structure an inherently unstructured activity. But I just hate to throw the baby out with the bath (and I think there is at least a tiny baby that can be spared by maintaining a some degree of a process orientation.
some assembly required
Yes there are any number of procedures we can use as resources and assemble as needed. Some of those procedures one might glorify with the title of "sub-process" but I don't like that term when there is no parent process.
And there is no parent process. The case changes state in response to information uncovered and external events, and actions taken. This is unpredictable.
We also have checklists of certain things that must happen in the case before it is done, and of things that should or could happen. MoSCoW. We also list input and output data artifacts that must, should or could be included.
And of course we have policy which defines principles, strategy, rules, guidelines and bounds.
That's the whole point of Case: there is no process but it can still be highly structured and controlled. We get locked into this thinking in IT that process provides controls. It is only one way and it doesn't work in unfamiliar situations.
recall also that we are only "abandoning" process for the Resolve step. All our receive, record, diagnose and categorise steps are unchanged before we get to Resolve.
SR vs INC
To throw a little bit of oil on the Service request vs Incident fire, I do think there is a difference between the two that justify different processes (or different handling).
The key distinction I typically make is that Service Requests can and should be planned, and can sometimes even be forecasted (frequency or period). Service Requests that are similar, could be grouped for more efficient execution. E.g. some companies still assign network folders manually, instead of handling each request individually, these could be optimized saying that those activities are done twice a week (e.g. monday and thursday). Focus is on planned, efficienty and timely implementation.
Incidents occur ad-hoc and should always be resolved ASAP, as it is impacting the end-user from using an already existing service.
This nature makes it a candidate for separating them.
However, any approach is fine with me: My motto is 'to make a clear decision, communicate it, and ensure you act upon it'. Too often these decisions are not taken, or not implemented, leaving all layers in the organization confused and acting differently.
incidents are requests
The only grounds I can see for separating incidents and requests is where one adopts ITIL's wacko concept of an incident without a user (or even a service interruption). To me an incident is a failure or perceived failure to deliver the expected service levels to a user or users. and the sole purposes of incident management is to restore the service or get the user to agree it cannot be restored.Pure and simple
if one accepts that definition then an incident is clearly a request to restore service .
Lots of request classes have a unique workflow and lots of classes are unplanned. There is nothing special about incidents.
Would you then agree...
Rob - Would you agree that there's no difference between walking into a store and buying something (perhaps asking a clerk where the item is located), and returning an item that is broken or which doesn't fit?
From the outside-in it remains a request for service
Roy
Accepted. There is a clear difference in the style and perhaps approach between a complaint/problem/issue/incident and the rest! But, from a customer perspective why do I care? Its a request for service. Sometimes, as a customer, I don't even know I have a problem sometimes. I've entered the Apple store numerous times with what seemed a simple question, only to uncover a potential issue resolved by a patch or update.
This is why I have always positioned an incident or whatever you want to call something that is out of the norm (not delivered or operating as expected) as a service request, type equals... it also vastly simplifies the provider side reporting, putting all causes for internal work effort in one handy container.
There is of course a
There is of course a difference. Great q, I blogged the answer
Lessons from healthcare case management?
Just a quick comment on ACM - and its 'recent discovery' here. Its a good thing. I'd urge my fellow IT professionals reading this blog to check out other service provider 'best practice', especially healthcare, which has a long history of 'case management' thinking.
At the core of ACM thinking and use is the recognition that the responder to a situation - a 'case (?)' may not have all the information at hand at the outset, or even during a response. The responder, or agent, must be able to adapt to circumstances, interactions, and additional information, and leverage and extend existing knowledge.
The procedure used in the response must be able to be adapted to the specific conditions encountered, and therefore prevailing governance (who is allowed to do what and under what circumstances) is a critical factor.
It was my experience working with healthcare case managers, combined with the thinking of luminaries such as Graban, Shaw, and Bitner, that led to how the USMBOK addresses the key discussion of service support and service request management and how in each practitioner guide we discuss the consumer scenario and need to focus on how key interactions are handled.
For ACM to succeed it must respect the DNA of a service request response, which include both a consumer and provider view - pathways, as suggested in the latest Lean and customer experience management writings. Else it will provide yet another inside-out set of thinking and methods.
These are just the type of conversations and discussions the service management profession should be having to ensure we are aware of and exploiting the very best (proven) guidance we can. Trying to make ITIL fit, or to argue that one framework is superior to another is a total waste of everyone's time.
ACM is yet another example of why we can't stand still when using frameworks such as ITIL and COBIT. We have been told for years to 'adopt and adapt' any guidance to make sure it works for a given situation. ACM reminds us we need to take an 'adaptive service management' approach...
And... posting new finds in the archeological dig of concepts and methods helpful to service management is a valuable service. Thanks Charlie and Skep for finding, reminding and sharing.
Keeping costs in check by leveraging BPM methods for ACM
I can see some parallels between your blogpost and an article I read advising to use existing BPM tools to give form to Case Management (via Slideshare: http://www.slideshare.net/capgemini/case-management-managing-chaos-unstr...).
Especially when starting with the cut between Standard and Case it seems appropriate to use the tools that staff already know and use. They'll be able to get their heads around the notion of Standard versus Case without the burden of having to learn how to use a new tool. They'll get to adapt their existing tool for as long as it is useful. Only after modifying it to the breaking point should a new tool be implemented.
My guess is that many tools will be able to accommodate such constructs.
technical solutions to non-technical challenges
yes i agree we can leverage existing tools for a long way into this.
Thanks for the reference to that paper. I only just got around to reading it. it does contain similar ideas and i got some new ones. Unfortunately, just like the "Adaptive Case Management" book, it looks to technical solutions to non-technical challenges: the broader behaviours and practices. Tools help they don't solve.
Also the Cap Gemini paper seems unable to let go of a process-centric perspective: it seems to see Case as a different kind of process, not a non-process. I guess if you want to use existing process tools you have to see it that way, but I found it uncomfortable.
A great read though. thanks again.
Service empathy
I like the standard versus case distinction and, although you recognize that "none of these categorisations should be overly visible to the user", would add that while a supplier has a process for dealing with standard requests, the poor old user often isn't aware of the fact that there's a standard solution for his/her needs. I (user) think I've got a case but you realize it's a standard request. In this situation I want to be treated differently than when I specifically ask for a standard solution. Therefore I'd add an optional pre-process that I've given a very concise name: 'Listen to the user, show that you're taking him/her seriously by pausing for a moment to think profoundly, then say "This will do the job mate"'.
Conversely, I might mistakenly ask for a standard solution while I actual need case-treatment. To ensure customer satisfaction, it's worthwhile applying judgement and assessing my level of competence then asking a couple of questions to verify that I'm on the right track. Preferably not leaving me with the impression that you think I'm an idiot. Which I may actually be. I might even be a case.
So there's a preliminary assessment/assurance/advice step. AAA, that's catchy...
The business case is not intuitively obvious
"No institution can possibly survive if it needs geniuses or supermen to manage it. It must be organized in such a way as to be able to get along under a leadership composed of average human beings."
Peter F. Drucker
As you well know, I'm not, necessarily a fan of all things ITIL. On the other hand, this change to ACM may put considerably more stress on the people working these "tickets."
If the overall outcomes are not obviously improved, and there is, at this point, little evidence to demontrate that, and the costs go up by requiring more training and better personnel, then we might want to consider examining the relative tradeoffs.
IT has to deliver at a cost.
I look forward to evidence of how this approach might relatively improve the results enough to overcome the rather obvious increase in costs.
In my experience (in tier 2
In my experience (in tier 2 and 2.5), those non-standard cases were escalated to engineering/sysadmin/whomever with their further troubleshooting and resolution, ideally, documented. (Though, often not.) Thereby providing the record for "training" etc. KCS anyone? This is not a new way of working, but It's a new label and a good way to package the concept of support.
not a new way of working
It's not a new way of working but it formalises the non-process-driven "exceptions" into a methodology and defines rules around who and when.
Even before it gets escalated to Level 2, such a case is often handed to the more experienced level 1 analyst to nut out what to do with it, i.e. to develop the case approach.
"cleaves" it more cleanly
Fair point... perhaps. I think it encourages specialisation into transactional Level 1 analysts who work to a script and a small team of more advanced problem solvers to work on the ill-defined Cases. That means we can focus specialised training on a smaller number.
I'm not sure it changes anything we do today - it just "cleaves" it more cleanly. We already deal wothj defined and undefined situations: this model isn't changing WHAT we deal with, just HOW. if that's true it may bring efficiencies not extra costs
Great Rob
Yes, the incident service request divide is useless and process approach has gone too far.
I also think that there must be change control but some companies are successful at driving change-release very fast and their approach looks different. It need further study.
I have been trying to tell people that it is time to forget old "best practices" and study new ones. ACM is clearly a very promising new practice and I recommend reading: Mastering the Unpredictable: How Adaptive Case Management Will Revolutionize the Way That Knowledge Workers Get Things Done.
Aale
I am reading Mastering the
I am reading Mastering the Unpredictable :)
Are we still thinking inside out?
In implementation I seldom split Servie Requests (or Access Requests) from Incidents. They make no sense to users who only want to scratch an itch. They sometimes mean something to IT (Service Requests may require authorization and should be automated, within reason), but the debate rages among little ITIL'ers (especially in LinkedIn groups) whether XX (i.e. password resets) are Incidents or Service Requests.
I doubt a new taxonomy will alleviate user confusion. Perhaps we need just "Requests". Then we can apply taxonomic principles to understanding their characteristics:
- Who generated the request (external customer, internal customer, user, internal provider, system/event)
- Degree of automation
- Degree of standardization
- Effort required
- Degree of approval required
- Degree of self-service
- Types of data artifacts to track
- Which services are relevant
- Requesting a new service versus accessing an existing service versus fixing a service
Eventually each organization may generate their own taxonomies, based on (most importantly) the needs of users but also how the organization meets them. Their solutions may or may not coalesce around current good practice frameworks such as ITIL or COBIT. To the extent we are still discussing what are service, service catalog, service request catalog, our answers will probably be different.
Moreover, as information and technology increasingly embed in the value network, the distinction between "user" and "provider" of IT will blur. We need to rethink this, and our conversations today will not make sense in 5 years.
As I understand ACM, cases involve document management and imaging capabilities that are not typical of ITSM tools. We may not be equipped to handle with current tools, but I am happy to be proven wrong on this. :-)
Not visible
It's not "inside-out" to think about how your system works internally. It is "inside-out" to ONLY think about how your system works internally, or to start from an internal view and work out to the customer. I have this argument with Ian Clayton: you can't ONLY think about IT from the outside.
This is a new taxonomy in the sense of categorising tickets, but it is not displacing the categorisation by request type, it is at right angles to it: I'm talking about a categorisation of how we deal with it
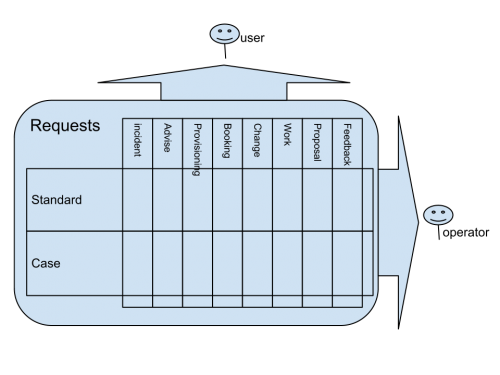
Any one of the classes of request that we use in order to decide WHAT action is required, can then be categorised by HOW we are going to deal with it: Standard process or Case management. For example many Provisioning (Access) requests will be Standard, but occasionally they will be unusual and need to be dealt with as a Case. Conversely perhaps fewer requests for Help will be Standard, and many will need individual attention as a Case.
I agree with you and others that none of these categorisations should be overly visible to the user. We don't need to tell them that "I am going to handle that as an Incident, in fact a Standard Incident". As far as users are concerned they are all Requests or Responses or Tickets or whatever you want to call them. (Occasionally we do need to explain why we are handling this request different to his last one because it is a different type)
I dont agree that current tools' ability to handle Cases is particularly relevant. I'm not going to not adopt a better way because my tool doesn't support it. I'll either (a) use the current too for Standard requests and a different tool for Case Management or (b) find a way to manage Cases in the existing tool even if it wasn't designed for it and extend it where necessary or (c) set the vendors salivating by looking for a new tool with both ACM and BPM capabilities. My initial suspicion is that current ticketing tools will be fine and Case requires advanced knowledge management capabilities where many of us have resorted to a separate knowledge management tool anyway because the ticketing tools suck so badly at KM. (Same issue when you try to do KCS, for example)
We agree more than disagree
Skep,
I won't defend outside-in thinking, because I haven't spent enough time with Clayton's proprietary USMBOK. Nor am I not going to spar with you in general because 1) I will lose those battles and 2) we agree far more than disagree.
When I referred to a taxonomy of generic "requests" I was not referring to ticket categorizations. Rather I was referring to how ITIL or other frameworks describe Incident, Service Request, Access Request, Normal Change, Standard Change, etc. I have one customer that categorizes Break/Fixes separate from Incidents--don't ask, I don't understand either. But undoubtedly there are characteristics that separate them from the perspective of their business (i.e. the impact) that may be relevant to the way they classify changes.
It looks like you are 2 years ahead of me on this matter anyway. http://www.itskeptic.org/list-request-classes-help-out-itil
Its not "my" outside-in...
Skep - you've had a copy of the 'proprietary' USMBOK in one form or another for a few years now. Its not alone in being the big 'P', count COBIT, ITIL, PRM-IT, ASL, even TIPU - its down to the author to decide how folks can access and use and at what cost.
The USMBOK approach to the humble service request has not changed since the first edition - an incident is one type of service request. It also lists seven other common types and emphasizes the discipline of 'service request management', linking a request to a service portal, service catalog, and more importantly a service request catalog.
The latest edition added the previous 'secret sauce' of outside-in thinking, completing the connection between a consumer scenario, the service request, its journey across the provider organization (pathway), moments of truth, workflow concepts, and 'cost of (service) request'.
Inside-out thinking focuses on the categorization and cataloging of requests. Outside-in thinking focuses on the cataloging of consumer scenarios and ensuring an appropriate response in the form of a service request pathway. If you are designing any of these common components of a service system without the scenario you are guessing - period.
The latest USMBOK also discusses in some detail the true role of service support (pillars of support) in enabling a customer engagement strategy exploiting social media, and how break/fix, helping hand, service recovery and complains and compliments elements are combined.... and how support can help design a better 'experience' and focus the provider efforts on aspects of the request response that has most effect on customer satisfaction.
By the way, its not my outside-in - wish I was that smart. Drucker, Normann, Levitt and Towers beat me to it and Patricia Seybold writes so much better than me on the topic! I prefer to say I am pioneering its application to the challenges of a service business and service provider organization - such as IT.
Let me know if you want to refresh your exe version of the USMBOK. See you at leadIT12.
the topic
I'm not sure what's proprietary about Tipu, given that it is in the public domain under a full-reuse commercial Creative Commons license.
I'm also not sure what this discussion of USMBOK content has to the application of Case Management to IT, which is the topic of this thread
USMBOK addresses service request management
Skep
The USMBOk was mentioned earlier in this thread and as I'm sure you recall it is ALL about how service requests are managed - both those responded to by humans and those by automation (service transaction engine). As some have indicated, it makes no sense to separate incidents from requests and the USMBOK has always regarded the former as a type of request. If you check again you will see at least 8 types of request mentioned.
In other writings we explain how a request must be wrapped in a customer engagement strategy to help manage the 4Es of expectation, the service (request) encounter, service experience and emotional genie. As for your comment about Case Management and the USMBOK - if you are introducing customer dynamics, what the USMBOK terms the consumer scenario, you are starting to address matters (finally) from the outside-in.
Service requests require an associated consumer scenario plus optional customer experience/engagement management concepts. Case management is a mature discussion and much of its approach was considered when developing the USMBOK - and encapsulated in the scenario catalog concept. This allows the service provider and often the service support function to identify specific scenario, match them in the response catalog, and externalize the dynamic aspects of service request management to allow for a fixed, repeatable, and standard operating procedure backbone...
It also describes a service request 'pathway' comprised of both a consumer and provider (perspective) pathway, allowing for different routes, sets of interactions and moments of truth based upon variations in the consumer scenario.
I'm looking forward to exchanging views on all this at itSMF's LeadIT12 on the Gold Coast.
Algorithms vs heuristics
I'd welcome more info on ACM, as this is how I think about it:
- algorithms: step-by-step procedures with standard approaches. Not much argument about these.
- heuristics: I always think of Atul Gawande's "DO-CONFIRM" checklist for cases. For instance, a prosecuting attorney doesn't have a procedure. S/he has a specific outcome desired and uses expert judgment to determine how well their argument will achieve the goal. Ideally, s/he has criteria that tends to determine success and evaluates against those items. S/he may even have a library of specific techniques that help to improve the argument against one or more criteria.
I'm on board with the efficiency versus effectiveness arguments against TPS and the like. They have their place, yet they tend to make for very fragile work flows.
Not only that...
First thing that came into my head when I read this was the fact that with this type of thinking, IT should not (can not?) force any type of terminology into the business. It sets the expectations around both things (i.e., when you call for this, this happens. When you call for that that happens) and that's it.
It makes it easier, more clear. Thanks for sharing, skep. ;-)
Yeah, you are right.
Yeah, you are right. As I cast my mind back over my years in support (levels 1 through 2.5) there was a clear workflow to whatever it was, or there was a clear workflow to a point (through troubleshooting) and then there wasn't anymore.
As far as change goes: it's either emergency or it isn't, and both need the change management process. I don't agree with ITIL's extra category of change that comes comes pre-approved. That one belongs with requests which should have the requisite documentation collected as part of the request fulfilment process, anyway.